AI-Powered Academic Integrity: Choosing a Plagiarism Detector and Similarity Checker


Plagiarism has been a long-festering issue for academic institutions, with the ease of access to a wider range of sources and the more recent developments of AI technology and text generators making it harder than ever to control. Understanding plagiarism and diving into what defines a similarity checker is therefore of utmost importance.
Academic institutions have a very specific set of challenges, so finding the right software to help – with more of a holistic approach to plagiarism detection – is key.
In this post, we’ll explain how, firstly, we can reframe our definitions of both cheating and plagiarism detectors and how that impacts the tool you choose. We’ll also explore the key metrics you’ll want to use to help find an appropriate solution.
Plagiarism Detection: Questioning the Terminology and Cheating Paradigm
![]()
Firstly, when exploring plagiarism in relation to AI-powered plagiarism detection, we find a more appropriate term to use is originality or similarity. Used widely in academic circles, similarity does not necessarily mean that the work is plagiarized. A paper could meet a predetermined, arbitrary similarity threshold without the intent to cheat.
As such, an element of human judgment is always necessary when determining whether a paper plagiarizes another or whether the similarities are balanced with enough original thought and interpretation that they justify being attributed to the author.
To add another layer of complexity, the widespread and rapid adoption of AI-powered text generation software makes it even harder for basic plagiarism detectors (also known as similarity checkers or detection tools) to identify where work is stolen (Weber-Wulff et al. 2023).
Content obfuscation en masse by an AI text generator can make it more challenging for some tools to determine whether work is stolen or, indeed, whether it is just generated by AI at all or actually authored by the student or academic submitting it.
So, it’s not just a question of finding a tool that can highlight passages of copied text – it’s important for all academics and students who are tasked with reviewing essays and publications to be re-educated on what is considered dishonest.
Simplistic tools produce a numerical value – cheat or not – whereas, if you look to a more advanced solution, you can provide formative feedback to show students and authors where they need to develop to produce work that does not cross similarity thresholds.
The definition of terms around plagiarism and similarity is key, as is this framing of what we mean when we discuss modern plagiarism. This will help to identify the best platform to meet the needs of the academic community.
The way that a platform identifies this terminology and the features it presents to tackle these broad issues will impact how suitable it is and how much it can simplify the process without levying unfair judgment on honest authors.
Similarity checkers or detection tools (what we’ll use in place of ‘plagiarism detectors’ from here on) are those that compare text with all other published works and websites online, looking to see where texts have been lifted or reproduced dishonestly.
They’re essential in modern academia. The internet may have made it easier than ever for students and other academics to access sources, but it, therefore, gives them more of an opportunity to take work and pass it off as their own.
However, as mentioned, it’s important to reframe your definition of plagiarism when looking for the appropriate software to tackle the issue. There are many free online plagiarism checker tools that are often way too simplistic to be of use, but to understand why, you need to examine the way these work, starting with meaning.
An accusation of plagiarism is a severe one, and assuming that all texts that share unreferenced similarities with other sources are an intentional malicious act can be equally harmful to the accuser as the accused.
The similarity index used in a typical plagiarism tool is not holistic enough for modern academia. They produce a set number based on limited models without nuance. Therefore, they are less of a similarity checker and more of a similarity indexer on a basic, limited level. (SA & Talha, 2019).
Having a system where you can push a ‘check plagiarism’ button and have it spit out an arbitrary number or a limited plagiarism report that only makes a decision based on a pre-set threshold is not helpful in developing students and can support false accusations.
Plagiarism can also be more sophisticated – where no words or phrases are copied, but the ideas are.
In their study of plagiarism detection tools, Tomáš Foltýnek et al. (2020) argued that many current systems are not sophisticated enough and determined that systems needed to identify more types of plagiarism better, cite sources, and produce more useful feedback when determining original work.
There are issues with translation plagiarism, too, where work can easily pass simple similarity checkers when translated from the original source (Memon, 2020).
It’s important to note the date of these studies and the leaps in technology that have been made by various providers to meet the demand since the Covid-19 pandemic started and the introduction of AI generation tools in late 2022.
Elements to Consider When Choosing a Similarity and “Plagiarism Detector”
![]()
Once terminology is defined, the next question is what criteria to use to judge a similarity detector. Shveta Miller has proposed five measurements at a broad level for pedagogical evaluation:
- Efficacy
- The Student Experience
- Intrinsic Motivation
- Zone of Proximal Development
- The Teacher Experience
Source: https://en.wikipedia.org/wiki/Content_similarity_detection
Of these, only two can intrinsically apply to similarity checkers – the efficacy of the tool and the experience it provides to academic tutors who are using it. Both are best judged on testimonials – the authentic reviews of past users who can share their positive and negative feedback.
You could also make an argument for the Zone of Proximal Development as being relevant. This is Vygotsky’s concept that refers to the zone where a student can achieve beyond what they have the skill to do when working unaided (Miller, 2020).
Tomáš Foltýnek et al. (2020) drafted a framework specifically related to similarity checking, dividing the criteria into two main groups – coverage and usability.
Coverage looks at how much of the known plagiarism was found in a text and how effective the system was at identifying it.
Usability then addresses how easy the system is to use, including how understandable the reports are, along with other practical elements, such as the cost of procuring the system.
While the references used in this paper are already outdated, more recent research is not yet available to draw upon. Many new tools have since emerged with more sophisticated algorithms (not least Inspera Originality). However, Foltýnek provides a reasonable framework for judging a tool’s suitability.
Types of Software-Assisted “Plagiarism Detection”
![]()
There are broadly two types of plagiarism detection – in text documents, comparing the language used in an essay or research paper, and in source code, which is a specific niche of its own, looking at where computing code has been lifted from other projects rather than written from scratch.
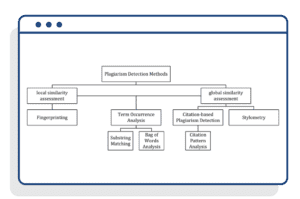
Focusing on in-text documents, there are several models employed by more traditional and limited similarity checkers, with most relying on one model. It’s always important to understand what makes a plagiarism checker work to understand its capabilities and, crucially, its limitations.
[insert image]
- Fingerprinting – breaking down documents into unique fingerprints through the cross-referencing of “n-grams”.
- String Matching – the most common and simplistic approach that compares exact matches of text, essentially a search engine for plagiarized content, looking at web page content and published online works.
- Bag of Words – examines documents from a numerical/vector standpoint, looking for similarities in word frequency, for example.
- Citation analysis – comparing the patterns of citations used.
- Stylometry – compares writing styles, including consistent (and inconsistent) elements.
If you use a similarity checker free of charge that you find online, it will likely offer only a simplistic version of one of these models. Even a paid-for “plagiarism scanner” may only focus on one or two of these at most.
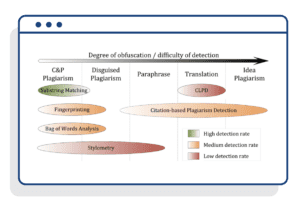
The difficulty of detection also varies based on the model involved – with some models exhibiting high obfuscation levels in certain plagiarism categories.
Source: https://en.wikipedia.org/wiki/Content_similarity_detection
Unlike the limitations of traditional models, Inspera Originality covers four of the main types of plagiarism – copy and paste (C&P), disguised plagiarism, paraphrasing, and translation, highlighting its effectiveness as a tool.
Inspera Originality is unique in that it doesn’t rely on these models; instead, it uses powerful AI technology to check for similarity in a more holistic way.
Evaluating AI-Powered Solutions
![]()
AI opens up some exciting opportunities for academics, including the potential for some significant enhancements in both the accuracy and efficiency of similarity checking.
AI-powered solutions such as Inspera Originality are able to use a broader range of checks against text, essentially being more thorough in how they analyze a submission.
It goes beyond a simple duplicated content search, instead producing accurate results against a wide range of potential plagiarism types. The word potential is key here, as we do not believe that any tool can say it actually detects plagiarism. They are there to assist, and the involvement of academic staff is paramount in determining if misconduct has actually occurred.
Inspera Originality captures more content that needs to be examined for potential plagiarism whilst ignoring work that other limited models may have otherwise flagged.
This makes the process more efficient, not only working at speed even with significant documents but also combining several checks into one whilst simplifying the reporting to make it easier for academics to use when providing feedback.
The aim is not to catch cheaters. It is to better educate students. With powerful AI-driven reporting, Inspera Originality is capable of producing more than just a set similarity index figure and, therefore, can facilitate student improvement through the qualitative, formative feedback it can provide.
AI-powered solutions are also best placed to help detect AI writing within papers, examining where students are likely to have relied on another AI tool to produce work rather than writing it themselves.
This helps to further ensure that almost all forms of potential plagiarism are captured and, ultimately, deterred.
Best Practices for Selecting an AI-Powered Originality – Not Plagiarism – Detector
![]()
As stated, a more holistic approach to originality checking is needed within the academic sector due to the unique challenges it produces. Academia is global – a single institution could be reviewing papers from across the world authored by writers of varying languages.
Plus, it is not about identifying a cheater, but supporting an author to develop their own writing, understand how to build on ideas rather than simply replicate them, and properly cite their sources.
As well as efficacy, factors such as compatibility and user experience are almost equally important, while support for multiple languages is also a necessity for most contemporary academic institutions.
Inspera Originality ticks all of these boxes, with three key elements for academics:
 Multilingual Similarity Detection
Multilingual Similarity Detection
Inspera Originality supports over 30 languages and can check a huge range of sources within those languages for similarity in written submissions.
Translation Similarity Detection
The system can also look at translation similarity, examining where writing may be a simple translated variation of existing work using any two of the languages within the system.
AI Authorship Detection
Inspera Originality can examine whether a submission contains any English-language content that has been generated by AI and make a prediction based on that analysis of whether AI has been used. It is then up to the academic to make a decision based on their knowledge of the author and previous work as to whether this is likely .
Through these models, Inspera Originality is able to capture a wide range of plagiarism types to help maintain academic integrity:
- Direct plagiarism – lifting work directly from other documents
- Paraphrase Plagiarism – where writing is copied but altered
- Mosaic Plagiarism – borrowed phrases or structures
- Self Plagiarism – repeating one’s own work without citation
- Inadvertent Plagiarism – use of information without citation
- Student Collusion – identifying similarities between separate submissions
- Software-based Text Modification – where writing is artificially altered to avoid detection of plagiarism
- Manual Text Modification – where writing is manually altered to avoid detection of plagiarism.
There are certain forms of plagiarism where Inspera Originality is not suited:
- Computer Code Plagiarism – lifting computer code directly
- Data Plagiarism – using data from other sources without citation
- Contract Cheating – where students hire a third party to author a document on their behalf
- Source Manipulation Cheating – where data sources are manipulated to provide false data.
By using Inspera Originality, you’re able to help educate both your fellow academic staff and your students about plagiarism.
It is not a system designed to sentence authors for cheating, but it can instead provide the feedback needed to help students understand what constitutes similarity issues and how they can grow their writing and abilities to provide authentic, original content.
Future Trends and Considerations

![]()
In terms of its lifespan, AI (in its practical uses for students) is still in its formative years, even if the sophistication of its output is rapidly improving.
However, AI advancements in maintaining academic integrity through more robust similarity checking tools, such as Inspera Originality, provide a means to match what text generators are capable of and how they can be deterred in students’ work.
There is a lot of potential for generative AI in higher education. When used correctly, it will empower students to more easily find sources of information that they can reference, whilst also providing a form of feedback to allow them to develop and refine their work prior to submission.
It’s far from perfect, and so the short- to medium-term future likely guarantees an increase in plagiarized submissions as students recreate information in more complex ways or fail to properly cite all of their research used.
This makes it even more integral to use an AI-powered system to help keep these trends in check. By staying updated with the latest AI technology, academics can ensure the integrity of their institution and that the work produced by its students remains at the highest standard.
The landscape for academic development is exciting but fraught with risk – tackling AI-powered plagiarism with an AI-powered “plagiarism detector” can negate that and help demonstrate to students the best way to employ these new tools available to them.
Final Thoughts
![]()
We all need to move away from a simplistic, index-driven view of similarity checking into a more advanced view, one that considers feedback and development is essential for academics who want to support their students whilst maintaining integrity.
That challenge is matched by the development of AI technology and its uses in creating plagiarized work – but this can be met by a contemporary and powerful system powered by its own AI.
Inspera Originality rises to this challenge effectively, not only being one of the best systems for capturing text plagiarism in all its modern forms but also helping to produce feedback that gives students the chance to grow and fulfill their potential rather than automatically vilifying them as cheaters.


